

Yesterday, Google announced a new tool in the beta version of Search Console (a.k.a. “the new Search Console.”) It’s called the “URL Inspection Tool,” and claims to “help you debug issues with new or existing pages in the Google Index.”
Google even goes so far as to make the bold claim that, with this tool, “If a page isn’t indexed, you can learn why.”
I would suggest they revise that to say “you might learn why,” because, in my experience giving this tool a thorough test drive today, it only proved useful some of the time.
Here’s a walkthrough of how I tested this tool, what I found it useful for, and what I found it absolutely useless for.
URL Inspection Tool Walkthrough
When I discovered that one of our agency Google accounts had access to the new tool (it’s still rolling out, so not all users have it yet), I found it in the left-hand sidebar under “Sitemaps.”
When I clicked on that, it opened a search bar at the top and offered me the option to “Inspect any URL” on my domain.

So, I started playing with different URLs on our site, starting with the homepage.
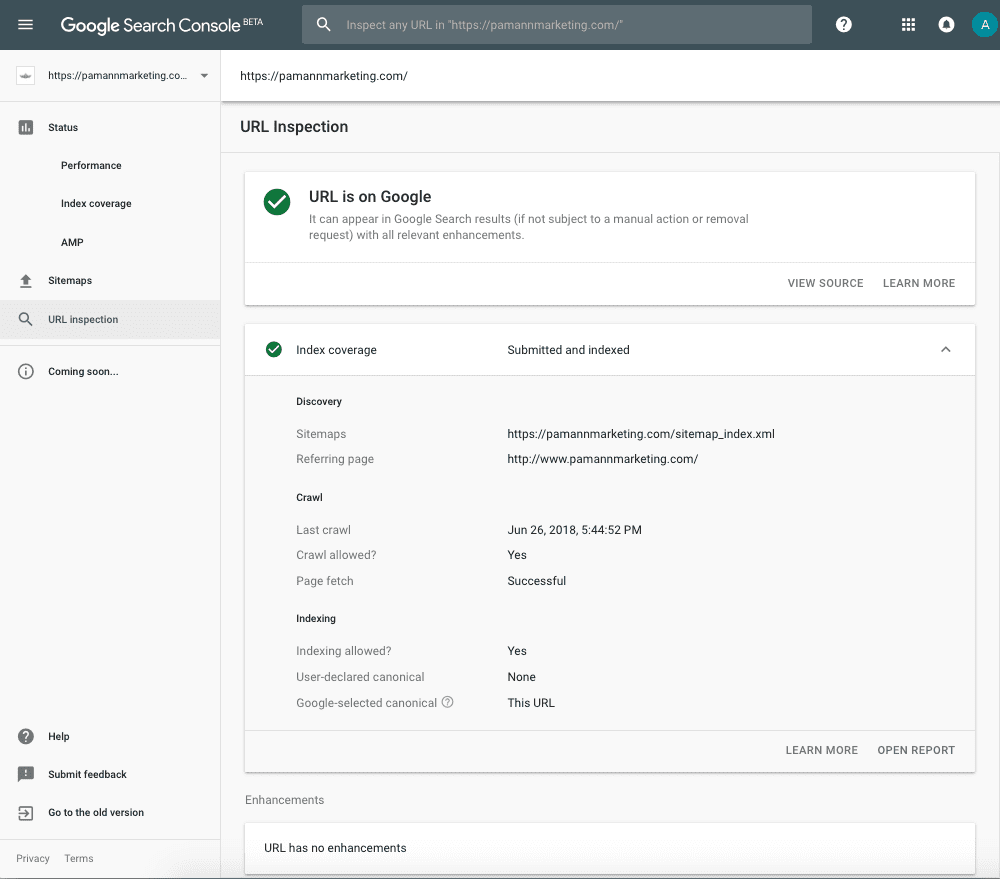
First Observation: “URL Has No Enhancements”
The first thing that struck me about this report was the part that said “URL has no enhancements.” I expected to see information there about the Schema markup that we have on that page since, according to Google, the enhancements section exists to show information about “structured data, linked AMP pages, and so on.”
But a quick skim through their documentation resolved my confusion about that. Apparently, not all structured data types are supported by the tool just yet. Only recipes and job postings are currently listed as supported rich results here.

The enhancements section did work when I tested an AMP-enabled URL, showing me that Google had discovered the linked AMP page and that it was valid.
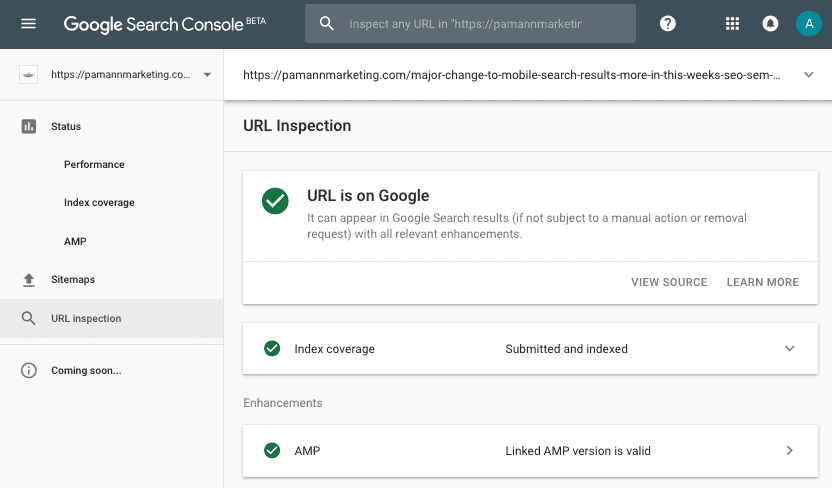
It also allowed me to drill down into the AMP result under “Enhancements” for even more details and confirmation that the AMP version was indexed.
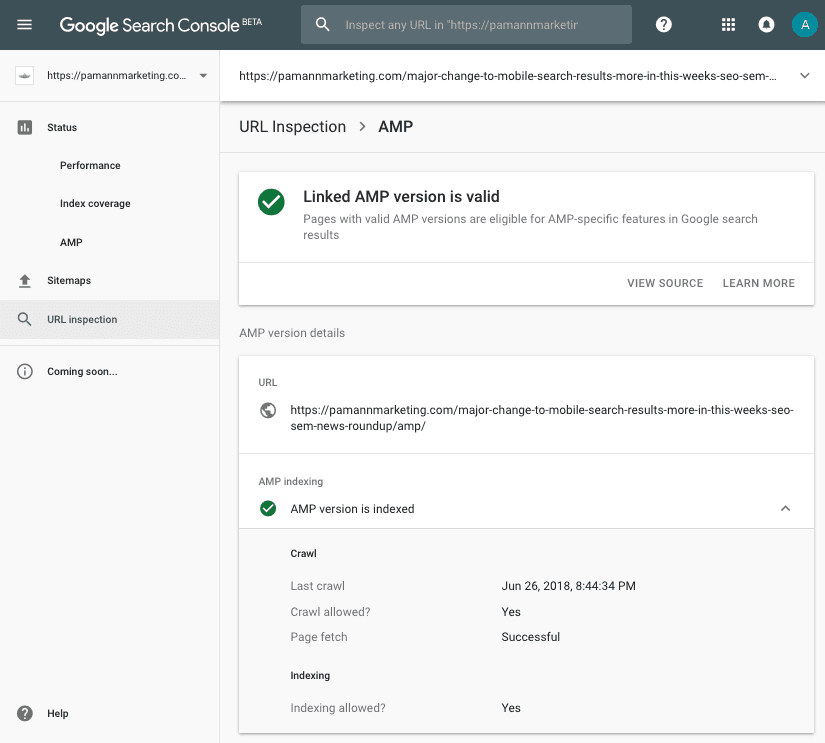
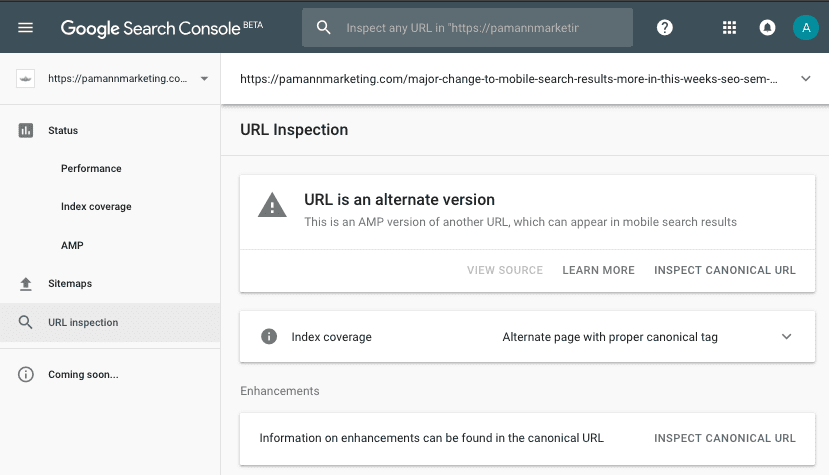
When I ran the tool for the AMP URL itself, it confirmed that the “URL is an alternate version” and offered me a quick link to inspect the canonical URL.
Second Observation: “User-Declared Canonical”
[Edit: As of 4:30pm ET on 6/28/18, this “none” issue seems to have been corrected by Google. Thanks to commenter Kristina below for giving us the heads up on that.]
The second thing that jumped out at me was that the “user-declared canonical” field said “none.” I know that we have implemented a rel=canonical tag on every page of the site, so that struck me as concerning.
A Twitter search revealed that other users were encountering the same issue, and tweeting John Mueller of Google about it. He indicated that they have received some feedback about that and intend to “make it clearer.”
We heard that from some others too — we'll see what we can do to make that clearer :-). Stay tuned & thanks for the feedback!
— 🐝 johnmu.rss?utm_medium=large (personal) 🐝 (@JohnMu) June 26, 2018
I’m not sure exactly what he means by that, but from further poking around in the tool, it seems to me that “user-declared canonical” is only populated when either it differs from the submitted URL, or when Google has selected a different canonical. If the submitted URL, canonical-tag-specified URL, and Google-selected canonical URL all match, then the “user-declared canonical” field will say “none.” That is indeed confusing, so I’m happy to see that Google is open to making some changes there. [Edit: As of 4:30pm ET on 6/28/18, this “none” issue seems to have been corrected by Google. Thanks to commenter Kristina below for giving us the heads up on that.]
Third Observation: The Manual Nature of the Tool, Followed by a Pleasant Surprise
At that point, I started checking other randomly-thought-of URLs from our site, and started to think about how manual of a process this was. I would think of a URL I wanted to check, manually enter it into the search bar, and review the results.
Who has time to sit there and do that all day, checking each URL one-by-one? That’s when it occurred to me that I should just be checking URLs with existing issues, and I turned to the Index Coverage report and went to the “Excluded” URLs.
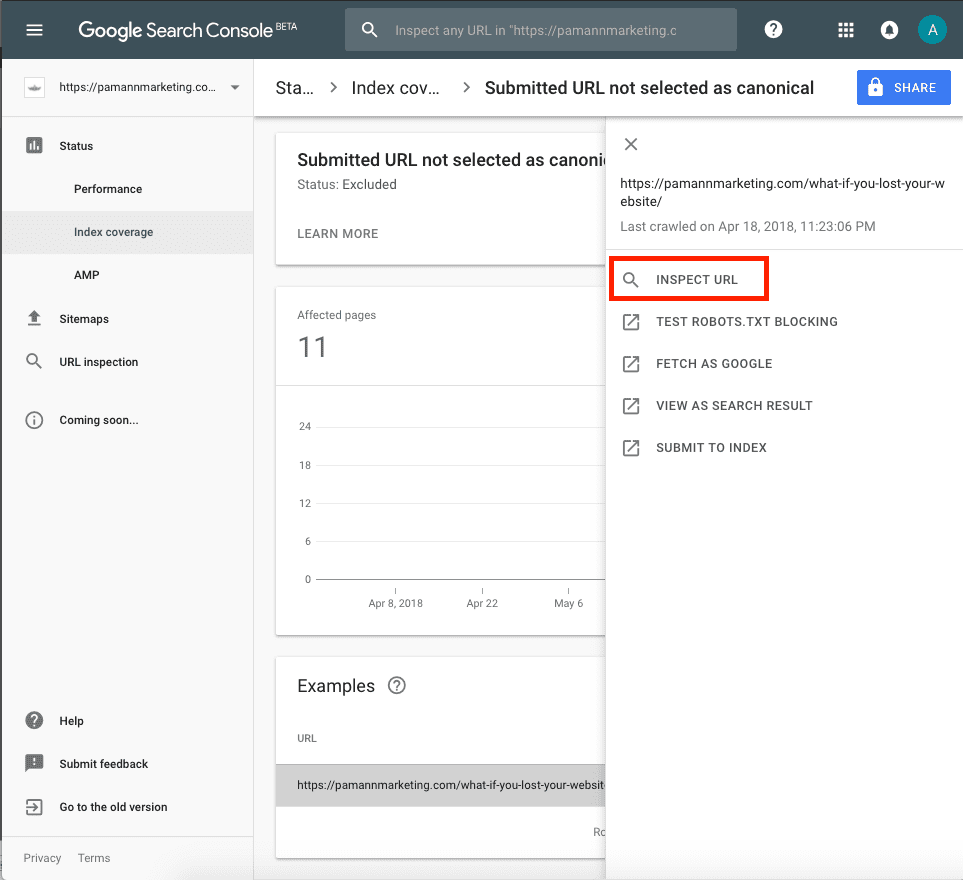
There I found a pleasant surprise! Clicking on a URL in the Index Coverage report now includes a handy little shortcut to run the URL Inspection Tool for that page. Now THAT could come in pretty handy.
First Inspection of an Excluded URL Proved Helpful, Although Not Entirely Accurate
This very first index-excluded URL that I inspected was from the Index Coverage report’s category called “Submitted URL not selected as canonical.” Obviously, I wanted to know why. After using the “Inspect URL” link in the Index Coverage interface to run the URL Inspection Tool, I received these results:
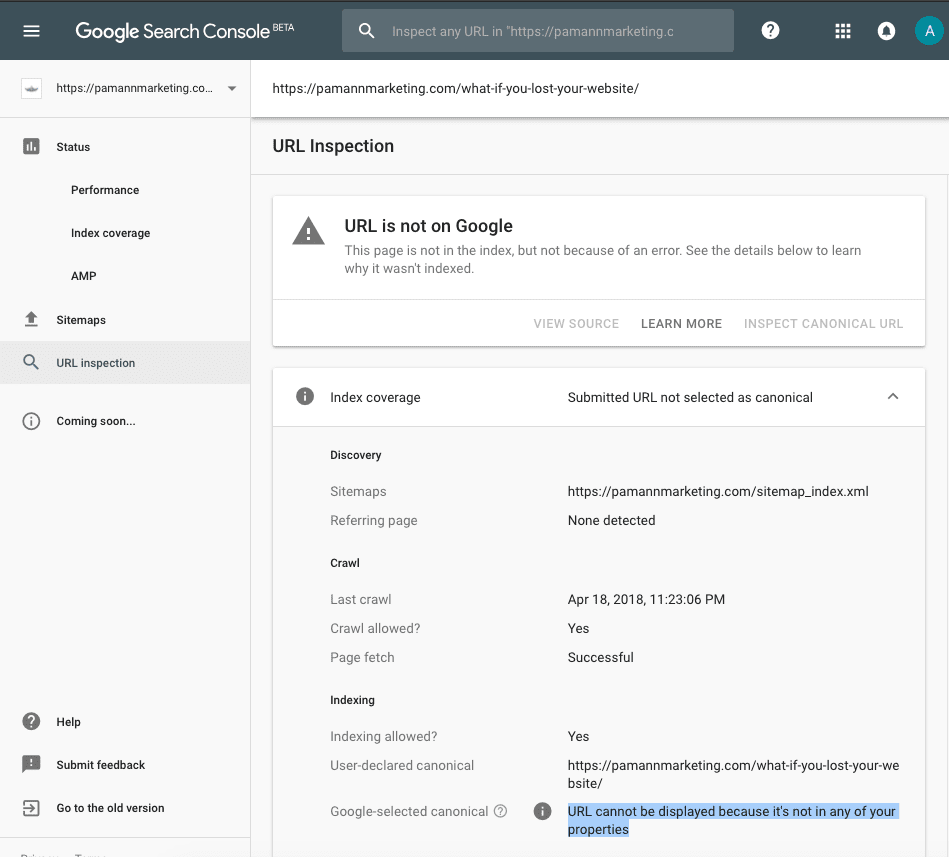
For a moment I was confused by that message, until I quickly realized it meant that Google selected a canonical URL from an external website (a different domain than ours.) That made sense in this case, because this article had been syndicated (with our permission) on another website. I knew that having an article syndicated on another website would lead to duplicate content and that Google would ultimately choose one of the sites to show in search results. In this case, it wasn’t ours.
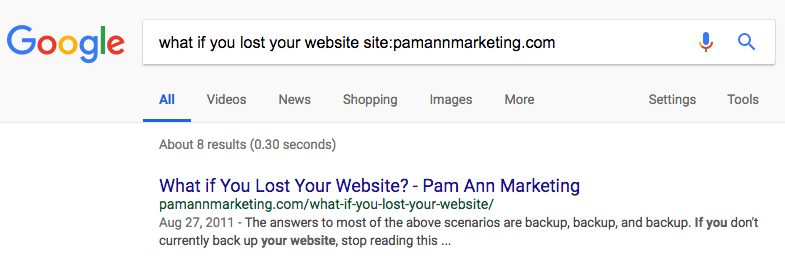
I’m okay with that, but just for the sake of curiosity, I did a “site:” search using our domain and found that Google did then show our copy in the SERPs, even though usually it shows the other website’s copy. I also did a quote-enclosed search of some of the content and found our copy in the “similar results” section.
So the tool is kind of lying by saying that this URL is “not on Google.” It’s obviously in their index, so that should be rephrased as “not selected for display in search results” – or something of that nature. But perhaps I’m splitting hairs here.
Other Inspections Weren’t As Useful, Contained Discrepancies
Next up, I checked another “Submitted URL not chosen as canonical” result from the Index Coverage report, and didn’t have as much luck getting useful information as to why. Even though the URL was clearly listed as “excluded” on the Index Coverage report, when I ran the URL Inspection, it provided a conflicting result, saying that the “URL is on Google” and that the Google-selected canonical was the same as the submitted URL. That is 100% in conflict with what the Index Coverage report just told me, which is that the URL was excluded from Google because the Google-selected canonical was different than the submitted URL.

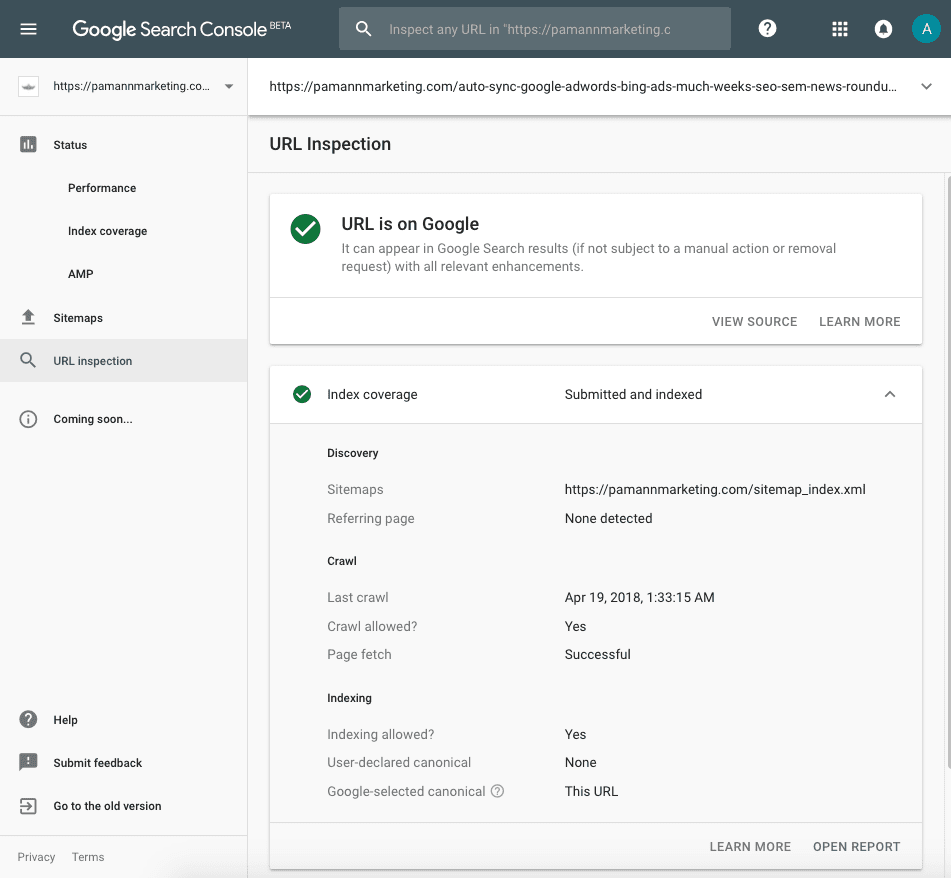
Upon further inspection, I realized I was repeatedly getting this conflicting information on WordPress attachment URLs. Apparently, we had been hit with this Yoast bug which turned attachment URL redirects off, when we had intended to have them on. This resulted in each image having both an image URL (e.g. /unique-image-name.jpg) and a non-image URL (e.g. /unique-image-name/). It made sense to me that Google would pick the image URL instead of the non-image URL for that type of duplicate content, and I suspect that’s what it did, but the URL inspection tool most definitely did not alert me to that as it is supposedly designed to.
Another Case of Uselessness
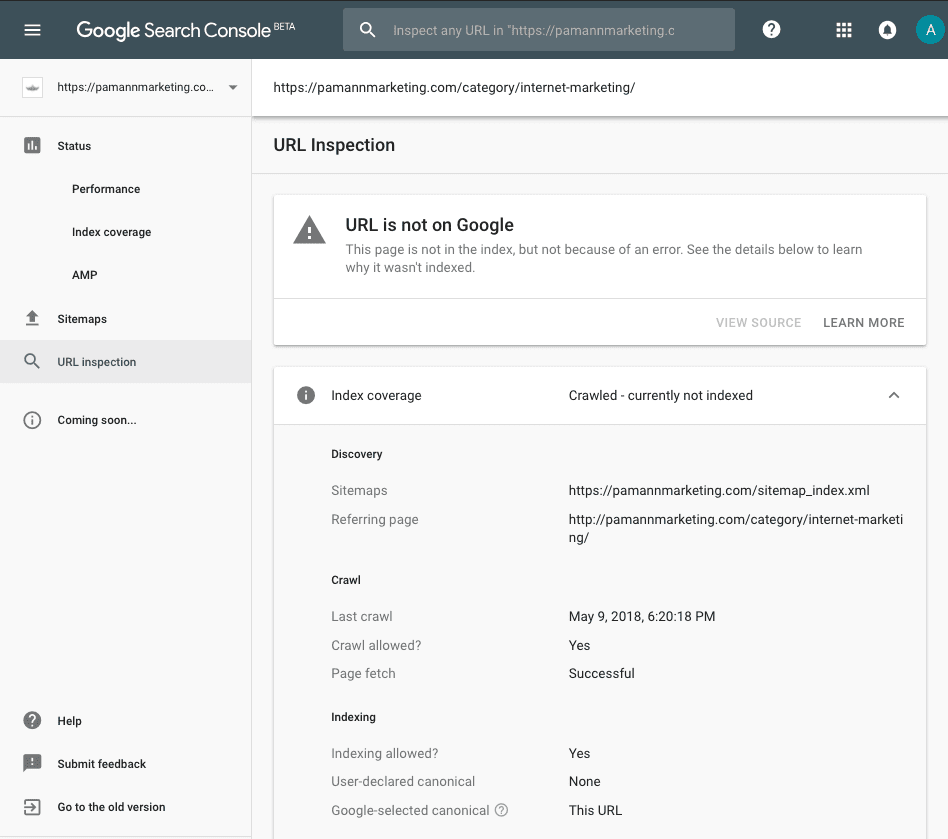
Next up, I checked a URL that was listed by the Index Coverage report as “Crawled – Not Currently Indexed.” I was excited to learn why. After all, Google’s exact words in their announcement about this tool were, “If a page isn’t indexed, you can learn why.” The tool itself even tells you to “See the details below to learn why it wasn’t indexed.”
Well, I didn’t learn why. The tool confirmed that the “URL is not on Google,” but indicated that the page was crawled and fetched successfully and indexing was allowed. I still have no idea why this page isn’t indexed.
Some Usefulness in the “Referring Page” Data
My next few test runs were almost-equally useless, except for the “referring page” information. In two cases, I found it useful to be pointed to the place where Googlebot discovered the URL at hand, or “possibly” discovered it, I should say. The documentation defines a “referring page” as follows:

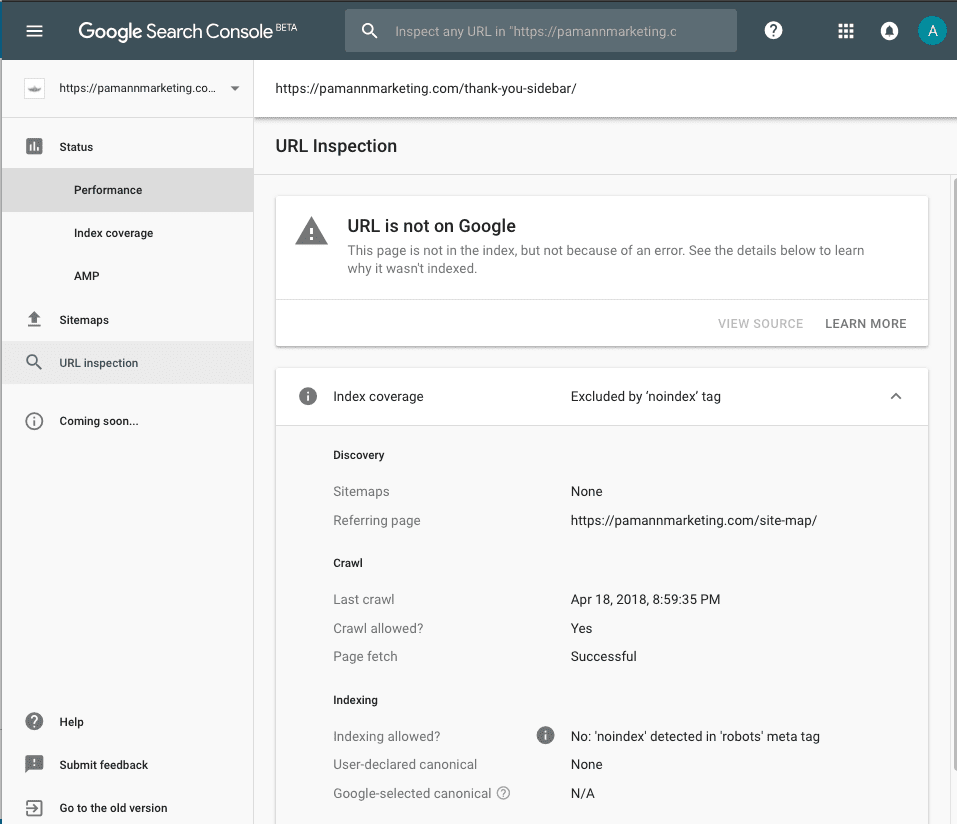
One of those cases was when I checked an “Excluded by ‘noindex’ tag” URL. We did intentionally mark this page as “noindex” because it’s a form confirmation submission page, but what I didn’t realize was that our HTML sitemap was still linking to it. That was useful information which I discovered through the “referring page” field on the results.
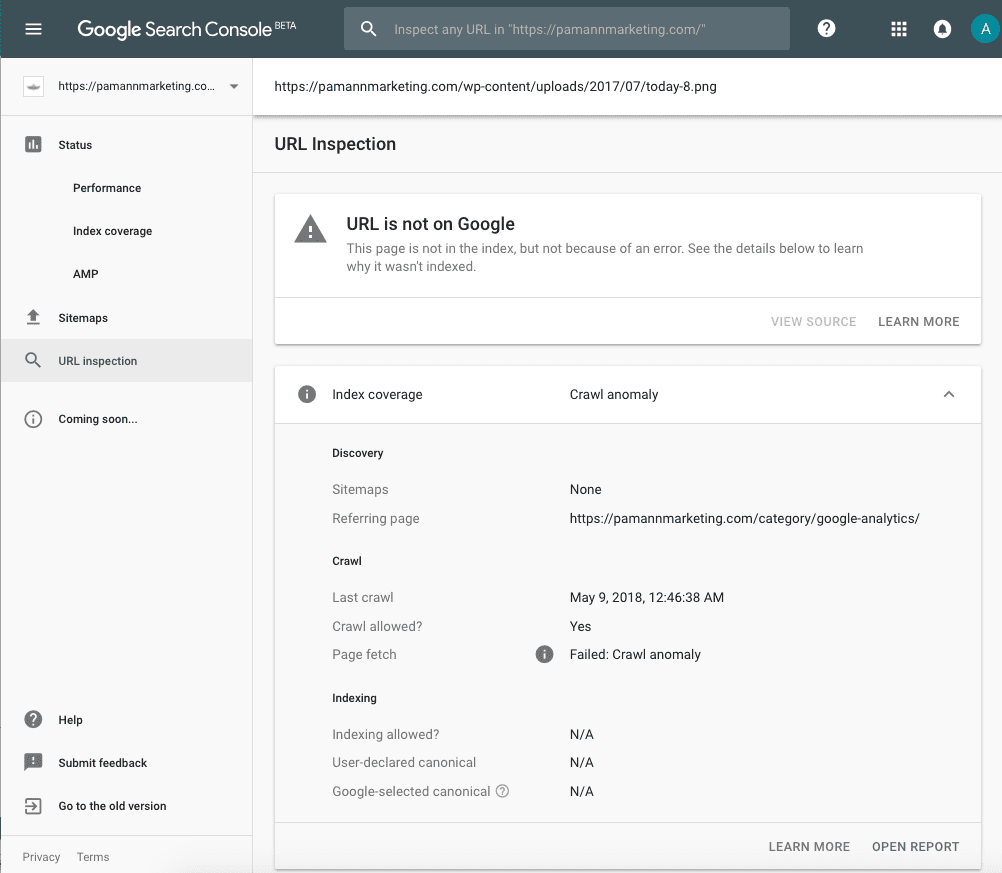
The next time I found the “referring page” data useful was when checking a “Crawl Anomaly” URL, which according to the Index Coverage report documentation means that “an unspecified anomaly occurred when fetching this URL.”
At first glance, the inspection result for one of these anomaly URLs seemed redundant, just simply reiterating that the fetch failed due to a crawl anomaly. But again, that handy little “referring page” field put me on to something.
I checked the source code on the referring page, and found that the URL at hand was actually a truncated version of a longer URL that got cut short by the Pinterest share button, in a jQuery script generated by said button. The “today-8.png” part of the URL was supposed to read “today-8-150×150.png.”
At first, I was confused as to why that didn’t simply generate a 404 crawl error, but then I realized that since the faulty URL was referred to in a jQuery script, and not a typical href tag, that could be why it caused a “crawl anomaly.” (I don’t know this for sure, but it makes sense in my head.)
So the URL Inspection Tool didn’t really give me any information directly about what caused this crawl anomaly, but it did give me the referring page, which in turn, allowed me to at least create a hypothesis as to what was causing the crawl anomaly.
Conclusion: URL Inspection Tool Falls Short on Its Grand Promises, but Can Occasionally Be Useful
I appreciate that Google is attempting to give webmasters more information about why certain URLs are not indexed, but overall, this tool fell short on that promise more often than not. That being said, the tool is brand new and released only in the beta version of Search Console, so we can’t expect it to be perfect right away.
There are several things that I found immediately useful in this tool, which are:
- The ability to confirm proper canonicalization, when a different URL is specified in the rel=canonical tag. I felt a sense of comfort being able to see with my own eyes that Google accurately understood and accepted our rel=canonical intentions, in the cases where it did. In my opinion, this is the most valuable function of the tool.
- Similarly, in cases where Google didn’t understand or accept our rel=canonical directives, seeing which canonical URL it chose instead was incredibly useful.
- “Referring page” data proved useful more than once.
- The ability to use the tool from a quick link in the Index Coverage report proved extremely handy for investigating “Excluded” URLs.
Things Google could improve upon:
- The very confusing fact that the “user-declared canonical” field says “none” unless the submitted URL has a rel=canonical tag pointing to a different URL, or Google has selected a different canonical URL on their own.
- It’s also confusing to be told that the “submitted URL has no enhancements,” when in reality, it does have structured data, but Google hasn’t added support for that type of markup to the tool yet. A simple re-wording of that response to not be quite so definitive (and inaccurate) is warranted in my opinion.
- Status discrepancies between the Index Coverage report, the URL Inspection Tool report, and presence of pages in the SERPs. Pages listed as excluded from Google in the Index Coverage report were sometimes reported by the URL Inspection Tool as indexed, and content available in the SERPs was sometimes reported by the tool as being “not on Google.”
- Complete failure to identify a reason for lack of indexation in some cases. When I was checking pages classified as”Crawled – Not Currently Indexed,” the tool simply confirmed that the page was crawled and fetched successfully, giving no explanation whatsoever for why the page wasn’t indexed.
Again, I appreciate any attempt by Google to give us SEOs more information, so kudos to them for that. I just hope that they continue to expand the usefulness and accuracy of this tool over time.
Need Further Assistance?
We offer coaching and training programs to help enhance your SEO strategy. Contact us to learn more!
- Google is Helping U.S. Government Sites Advertise the Sale of Illegal Drugs - October 16, 2024
- Google Has Been Ruled a Monopoly in Antitrust Lawsuit (Video) - August 9, 2024
- New Domain or Subdomain? Which is Better for SEO? - October 13, 2023